I had a conversation recently with a respected psychometrician. Someone truly smart and thoughtful, whom I personally respect for a variety of reasons. I take what they say and write quite seriously—even though I don't necessarily agree with all of it.
In the course of the conversation, he made a point about psychometrics and validity that required, as far as I could tell, simply setting aside what The Standards for Educational and Psychological Testing say on the matter. When I pressed him on it, he dismissed my reference to The Standards by saying—in a kidding-not-kidding sort of way—"I don't care what The Standards say."
I don't buy it. I know that he cares—just not enough to let it stop him. And not enough to reckon with the inconsistency between The Standards and the argument he wanted to make. So he made the joke rather than wrestling with what the document actually says. The humor was doing epistemological work by signaling that the authoritative, hard-won, cross-disciplinary consensus document was beneath the level of argument he was operating at. It was clearly a joke. It was also a deflection.
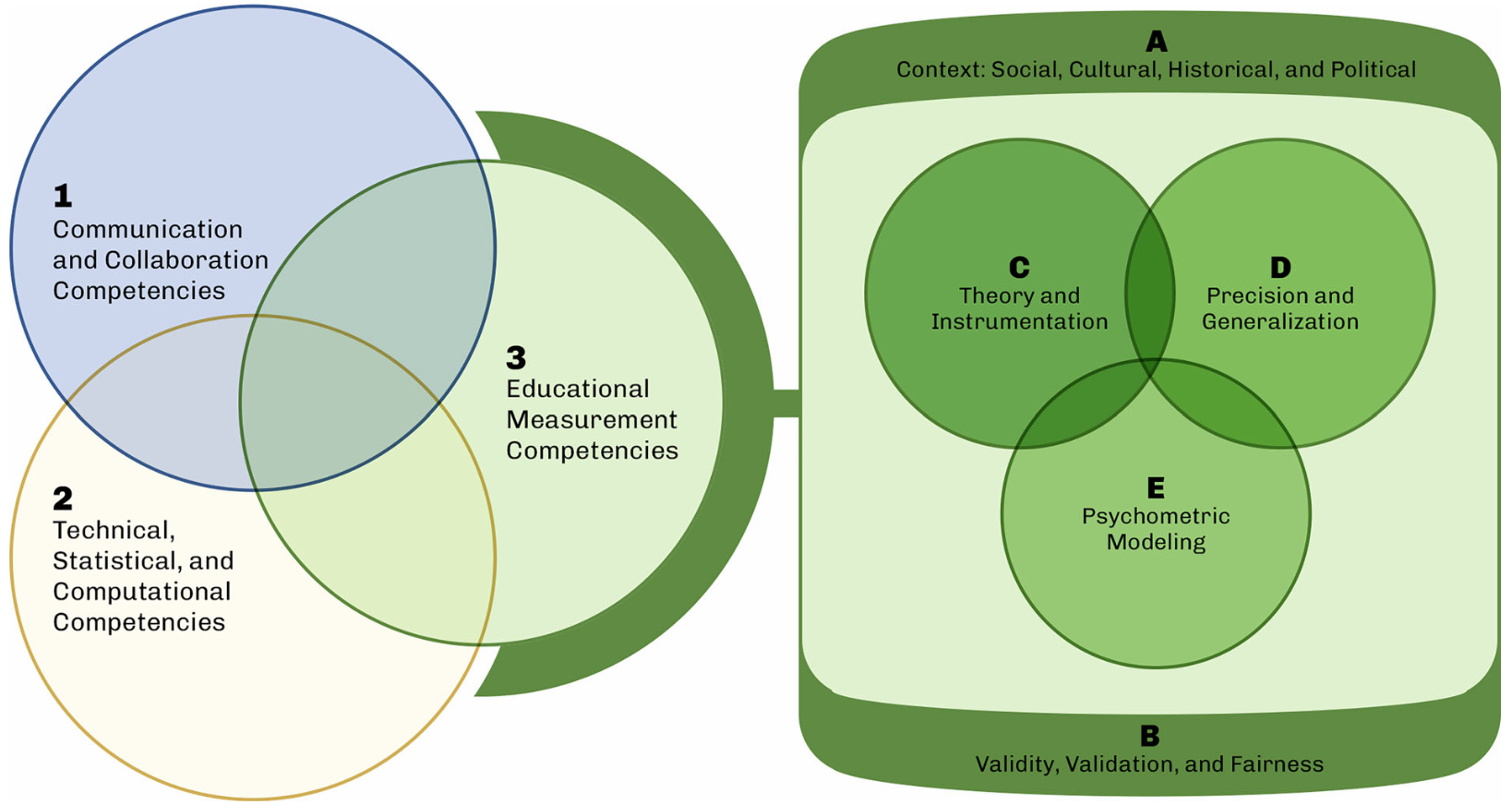
So I pushed further. He then dismissed The Standards as merely "a consensus document"—as though that fact diminishes its authority rather than constituting it. In word-oriented epistemologies, in law, in democratic theory, consensus is the source of authority. The Standards carry weight precisely because they represent serious, collaboratively arrived-at agreement over the course of generations across the constituencies of this multi-disciplinary field. That is not a weakness. That is what they are. They should not be ignored for being inconvenient, or dismissed for failing to feature one's own favorite ideas. (RTD, for example, adds item validity to the picture The Standards draw—but removes nothing from it in order to do so.)
Then he asked whether domain models can be falsifiable.

For a third time, I was stopped cold. The domain models given to assessment developers are the job. State legislatures ratify learning standards. Test development contracts call for assessments to align with them. And like The Standards, the standards themselves represent the product of generations of thinking—about curricular priorities and learning sequences. Modern standards can be traced through the remarkable work of the National Council of Teachers of Mathematics in the 1980s and 1990s and through the broader education standards movement that followed. This is serious work, done by people deeply committed to their fields and to their students.
Are they falsifiable? From a Bayesian perspective, it would take an extraordinary amount of evidence to do so—certainly astronomically more than can be generated by convenient but obviously inappropriate psychometric models. And any such evidence would have to address the actual concerns of the standards: the nature of the content and the appropriate learning sequences through it. None of that was on the table. Moreover, what would result from that kind of serious engagement would be iterative improvement, not disproof. That is how both The Standards and the standards develop over time.
Asking whether they are falsifiable is a category error. Falsifiability is a criterion native to one epistemological tradition—a powerful and important tradition—being applied as though it were universal. CCSS is not a hypothesis. It is a social, legal, and professional agreement about what students should know and be able to do and how those learning goals hold together. The right question is not can it be falsified? The right question is is our test properly grounded in it? That is word-oriented epistemology's home territory. And it is, not coincidentally, the epistemological tradition that The Standards themselves are working in.
So, in a single conversation, the same move was made three times. The Standards—dismissed with a joke. The learning standards—subjected to a criterion from a different epistemological tradition that was never designed to apply to them.
This is not a story about a bad actor. It is a story about a larger trap—about what happens when deep disciplinary formation leads someone to stop seeing the obligations that don't fit its framework. This psychometrician spoke from genuine expertise. But for decades, this is the view I have seen dominate educational measurement. And it stands in the way of high quality assessments—and of the respect from educators and the broader public that high quality assessments deserve.
This is not to say that The Standards and the standards act like laws of nature. They are not absolutely inviolate. Nature says that nothing can travel faster than the speed of light. But the 613 mitzvot in the Torah—commandments that have structured Jewish life for millennia—all yield to pikuach nefesh, to the preservation of life. There are hierarchies among them. There are millennia of accumulated debate about how to understand and implement these written words. Some communities have revised their relationship to them substantially. But none of those debates—not the Talmudic tradition, not Reform Judaism, not the interpretive traditions of Christianity—simply dismiss them. Even where traditions have departed from strict observance, they have done so through serious engagement, not jokes and deflection. The wrestling is the point.
The Standards and the standards work the same way. They have hierarchies—Andrew Ho has argued that the first source of validity evidence is listed first for a reason, and he is right. They require interpretation. They will be revised, and there are people doing that work on The Standards right now. They will listen to the entire professional community. That is how both bodies of work grow and improve. Not through dismissal, but through serious engagement by people who take them seriously enough to push back on them in principled, argued, evidence-based ways.
But until that revision work is done—until the community has done the wrestling and arrived at a new agreement—we are all professionally obligated to respect both The Standards and the standards. They define the job. Without them, we would be flailing, each of us alone, trying to figure out what we are supposed to be doing. With them, we stand on the shoulders of those who came before us.
That is what escaping the trap looks like. Not abandoning your formation. Not pretending that all methods are equally appropriate for all questions. But recognizing that your framework is your framework—powerful and not universal—and that the standards and The Standards deserve grounded, serious engagement. The Standards and the standards merit deference from all of us because they are the product of multiple epistemologies and disciplines. They should guide us in transcending our own.