Andrew Ho seems to be obsessed with the challenges of communicating findings or results from the field of educational measurements to other experts in our field, to true experts who make professional use of the products of our work and even to a broader public. His predecessor at HGSE, John Willett, certainly drilled into my head that communicating quantitative results accurately is at least as important at arriving at them. Andrew only tempers that idea insofar as seriously considering the (almost certainly) inevitable tradeoffs between clarity to those various audiences and strict accuracy.
That’s a really good obsession to have. Sure, Andrew’s challenge to students is far greater than John’s, in part because it is about trade-offs and values. And because we have to imagine how an audience unlike ourselves might make sense of something. And because the most salient difference between them and ourselves is what we are most obsessed with. That is, we have devoted our professional lives to understanding something deeply, to advancing it, to making expert use of it at the highest levels, and they are uninterested in any of the details that so interest and engage us.
Another of my favorites, Charlie DePascale, has again responded to some of Andrew’s offerings, focusing for now on one particular graph from Andrew about those tradeoffs between accuracy and clarity. Andrew wisely builds on the idea that we cannot get to clarity without an engaged audience, and therefore an engaging manner of comminucation.
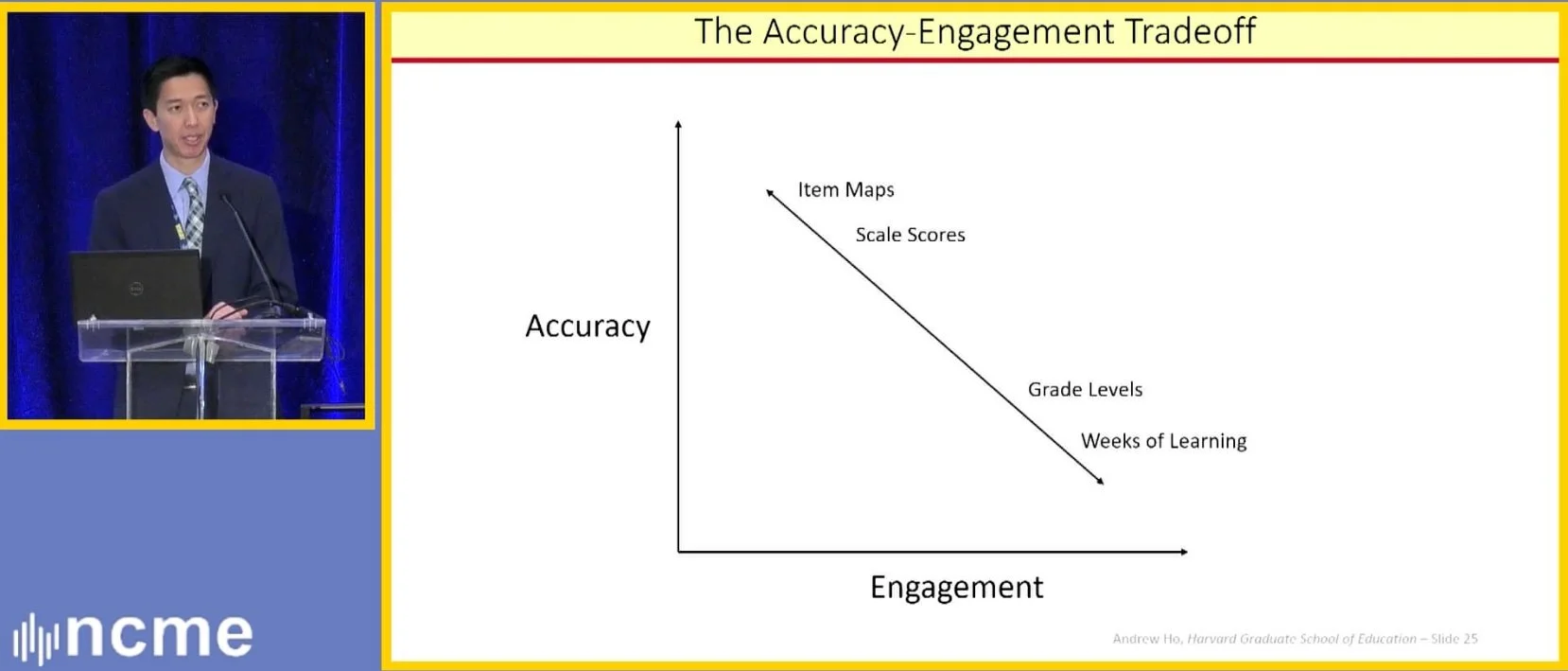
Andrew Ho’ Accuracy-Engagement Tradeoff
I agree with Andrew’s principles, and I agree with Charlie’s disagreements and particulars. But I think they are both barking of up the wrong tree, which Charlie almost acknowledges.
Also not mentioned are scores such as subscores and mastery scores, which have the potential to be both highly accurate and engaging, but unfortunately not when generated from large-scale, standardized tests analyzed with unidimensional IRT models.
The challenges of communicating with those various audiences about test taker performance and test proficiencies are real. They are multitudinous and layered. Some of them are nuanced. Some of them are quite technical. But there really is one root problem with communicating the meaning of standardized test score: they are false.
As Charlie came so close to suggesting, the problem is the use of “unidimensional IRT models.” Unidimensionality is the original sin in all of this. The task that Andrew is trying to apply his obsession with communications to is communicating the meaning of unidimensional scores to report on multi-dimensional constructs. Reading and writing collapsed into one score. Reading informational texts and literary texts into one score. Diligent capturing of explicit details in a text and considering the implications or larger themes in one score. Or, sloppiness with computation with the ability to see a solution path to a complex math problem in one score. Or, skills with the abstractions of algebra and the concreteness of geometry in one score. Skills with the algorithms of calculating area or volume and the logical reasoning of the geometry proof in one score.
The tests do not and cannot capture proficiencies with the full breadth of the content in the limited time available for standardized testing, so to report a singular score on “math” or “geometry” is necessarily to communicate something untrue. But even if there were more time available, the fact is that some students or test takers will do better on some things than on others. And some things in the domain model are more important than others. And certainly, in practice we violate the many assumptions of sampling that are necessary to make any inferences at all from test results, but are even more important to the fiction of unidimensional reporting based on such limited tests.
Content development professionals need to figure out better ways to assess the content, yes. And that is where my work focuses. But psychometricians and high level policy-makers must find far better ways to report on performance. Unidimensionality itself is strong evidence against validity, as it is plain and clear evidence that the internal structure of the data (i.e., the third type of validity evidence in The Standards) does not match that of the content area, domain model, or even the test blueprint. Sub-scores can be engaging and meaningful, but cannot be accurate, as Charlie wrote, “when generated from large-scale, standardized tests analyzed with unidimensional IRT models.” And the fact that the demands of such models act as a filter on what items might even be included on a test means that they are actively used to undermine content representation on tests (i.e., the first type of validity evidence in The Standards), thus are a direct cause for worsening evidence based on test content .
Or, to return to Andrew’s 3 W’s, “Who is using Which Scores and for What purpose?” Whether we are evaluating individual students, teachers, curricula, professional development programs, schools or district leadership, district or state policy, the purposes to which we want to put the tests are not met with unidimensional reporting. We always want to know what we are evaluating is good at and what it is bad at, so that we may address those weaknesses. Assuming, claiming, asserting and insisting that multi-dimensional constructs can be accurately or engagingly reported on unidimensionally is just a bad idea. The only people who favor such a thing do not actually have to interpret or make use of them for any purposes, but would like to simplify the world so they do not have to actually understand the complex decisions and tradeoffs of those who do.
Or, to steal and redo Andrew’s graph…

Accuracy-Engagement Tradeoff for Unidimensional & Multidimensional Results
I agree with Andrew that there is often a trade-off between accuracy and engagement—and therefore clarity—though I am not convinced that it is always zero-sum. More importantly, whatever the sum is, it is lower when reporting the false simplifications and fictions of unidimensional results than more useful and meaningful multidimensional results.
I know that IRT is cool. I know that it has mathematical elegance and real conceptual strengths, as Andrew’s other predecessor at HGSE taught me. But the use of unidimensional psychometric models should be limited to measuring and reporting on contracts that the subject matter experts believe are unidimensional.